The Node.js project has been working on implementations of standard web platform APIs, such as the WHATWG URL parser, AbortController, EventTarget, TextEncoder, Web Crypto API and more. The latest effort underway is to implement support for the Web Streams API. Here, we dig into some of the details of that new implementation and show a little of what it will enable in Node.js.
Creating and using a ReadableStream
A ReadableStream is an object for processing inbound streaming data. Every ReadableStream has what is referred to as an "underlying source" -- an object from which the streaming data originates, and a "controller" -- an object responsible for managing the ReadableStream's internal state and queue. The underlying source and the controller cooperate to provide the data that is made available via the ReadableStream.
In this example, we create a ReadableStream from an underlying source that uses the controller to enqueue a timestamp approximately once per second:
import { ReadableStream } from 'node:stream/web'
import { setInterval as every } from 'node:timers/promises'
const SECOND = 1000
const readable = new ReadableStream({
async start(controller) {
for await (const _ of every(SECOND)) controller.enqueue(performance.now())
},
})
for await (const value of readable) console.log(value)When the ReadableStream is created, the underlying source's start() method is called, which, in this case, starts an async iterator using Node.js' awaitable timers API. Approximately once per second, the underlying source calls controller.enqueue() to push a new timestamp into the ReadableStream's queue. We then use an async iterator to read the timestamps from the ReadableStream itself. (One thing that you should notice immediately is that the timestamps are not consistently exactly one second apart, that's because timers in Node.js are imprecise and ReadableStreams add additional overhead due to promise microtask handling).
As an alternative to using the async iterator, we can acquire a reader and request data from the ReadableStream one chunk at a time:
const reader = readable.getReader()
const { value, done } = await reader.read()
console.log(value) // The value that was read
console.log(done) // Indicates whether we're done reading or not.One critical concept for web streams is the fact that the ReadableStream itself does very little. It is the underlying source that is responsible for doing the heavy lifting in regards to providing the data to the ReadableStream object. The underlying source is implemented as a simple object that optionally exposes three methods: start(), pull(), and cancel():
const readable = new ReadableStream({
start(controller) {
// Called immediately when the ReadableStream is created.
},
pull(controller) {
// Called immediately when the ReadableStream is created,
// and again whenever the internal queue is not full.
},
cancel(reason) {
// Called when the ReadableStream is canceled.
},
})The methods may be synchronous or asynchronous (that is, they may return promises).
The start() method is called immediately when the ReadableStream is created, and is responsible for setting up the flow of data. For instance, in an underlying source that reads file data from the file system, the start() method is where you would open the file handle that is to be read from.
The pull() method is called by the ReadableStream whenever its internal data queue is not full and more data is needed. It is responsible for pulling another amount of data from the underlying source into the stream. If this method returns a promise, pull will not be called again until after that promise is fulfilled, providing for a natural backpressure model in which a consumer is not able to try reading data from the underlying source faster than it is actually available.
The cancel() method is called when the user code has signaled that it is no longer interested in the data provided by the underlying source. This is where the underlying source should perform any clean up actions, such as closing a file handle or a remote data connection.
In most cases, the underlying stream will create the chunks of data that are read and will push those along to the user code. For some kinds of data, however, this can be inefficient due to extraneous copying of the data buffers. The web streams ReadableStream API allows for a more efficient, yet a bit more complicated, API pattern called the "bring your own buffer" -- or BYOB -- reader. With this pattern, the user code will allocate a buffer that the underlying source will fill with data.
In this example, we create a ReadableStream that fills the user-supplied Uint8Array with cryptographically random data:
import { ReadableStream } from 'node:stream/web'
import { randomFill } from 'node:crypto'
const readable = new ReadableStream({
type: 'bytes',
pull(controller) {
const byobRequest = controller.byobRequest
return new Promise((resolve, reject) => {
randomFill(byobRequest.view, (err) => {
if (err) return reject(err)
byobRequest.respond(byobRequest.view.byteLength)
resolve()
})
})
},
})
const reader = readable.getReader({ mode: 'byob' })
console.log(await reader.read(new Uint8Array(10)))Note the key differences here between the first example (pushing timestamps out once every second) and the second (filling a user-provided buffer). In the first, the underlying source is able to proactively keep pushing data into the ReadableStream on its own, even if the user code is not yet directly interacting with the stream. In the second, the underlying source must wait until the user code supplies a buffer for it to fill. The ReadableStreams API allows for much more complicated scenarios that combine elements of both push and pull models that we won't get into here.
Writable Streams
A WritableStream follows the same basic pattern, except for outbound streaming data.
The WritableStream is created with an object called the "underlying sink", it is the destination to which the streaming data is delivered. Like the ReadableStream, the WritableStream also has a controller that is responsible for managing it's internal state.
In this example, we create the simplest kind of WritableStream that merely prints the written chunks to the console:
import { WritableStream } from 'node:stream/web'
const writable = new WritableStream({
write(chunk) {
console.log(chunk)
},
})
const writer = writable.getWriter()
await writer.write('Hello World')The WritableStream API really does not care what kind of data is being written. Any JavaScript value can be passed to the write() method and it will be forwarded along to the underlying sink, which has to decide whether it can work with the provided data or not.
As the WritableStream object is operating, it will call four methods optionally exposed by the underlying sink.
const writable = new WritableStream({
start(controller) {
// Called immediately when the WritableStream is created.
},
write(chunk, controller) {
// Called whenever a chunk of data is written to the stream
},
close(controller) {
// Called when the application has signaled that it is done
// writing chunks to the stream.
},
abort(reason) {
// Called when the stream is abnormally terminated.
},
})The start() method here, like with ReadableStream, is called immediately when the WritableStream is created. This is where any initialization steps should be completed.
The write() method, unsurprisingly, is the method the WritableStream calls whenever a chunk of data is passed into it. If this method returns a promise, write() will not be called again until after that promise is fulfilled.
The close() method is called when the code writing to the WritableStream has indicated that it is done doing so, and the abort() method is called when the WritableStream is abnormally terminated.
The ReadableStream and WritableStream APIs are designed to be complementary. In the following example, the ReadableStream is asked to forward it's data to the given WritableStream, returning a promise that is fulfilled once all of the data has been transferred.
import { ReadableStream, WritableStream } from 'node:stream/web'
const readable = new ReadableStream(getSomeSource())
const writable = new WritableStream(getSomeSink())
await readable.pipeTo(writable)In this case, the underlying source and underlying sink must agree on the type of data that is being streamed. Whatever type of data that is, it is entirely opaque to the web streams API itself. When the source and sink have different expectations on the kind of data being worked with, a TransformStream can be used to bridge the requirements.
Transforms
A TransformStream is a special object that exposes a WritableStream and a ReadableStream. Data written to the WritableStream is optionally passed through a transform() function to be mutated or replaced before it is passed on the ReadableStream for consumption.
In this example, for instance, we create a TransformStream that merely converts written strings to uppercase before forwarding those on:
import { TransformStream } from 'node:stream/web'
const transform = new TransformStream({
transform(chunk, controller) {
controller.enqueue(chunk.toUpperCase())
},
})
const writer = transform.writable.getWriter()
const reader = transform.readable.getReader()
writer.write('hello world')
console.log(await reader.read()) // HELLO WORLDThe the ReadableStream pipeThrough() method, we can easily create a pipeline through which data can flow from an originating ReadableStream, be transformed, then be forwarded on to a destination WritableStream:
import { ReadableStream, TransformStream } from 'node:stream/web'
const readable = new ReadableStream(getSomeSource())
const transform = new TransformStream(getSomeTransformer())
const writable = new WritableStream(getSomeSink())
await readable.pipeThrough(transform).pipeTo(writable)The TransformStream is created using an object called a "transformer", which optionally implements three methods:
const transform = new TransformStream({
start(controller) {
// Called immediately when the TransformStream is created
},
transform(chunk, controller) {
// Called for every chunk received by the WritableStream
// side. The chunk is modified, then forwarded on to the
// ReadableStream side via the controller.
},
flush(controller) {
// Called when the WritableStream side has finished
// forwarding chunks on to the transformer.
},
})Like both the ReadableStream and WritableStream, the start() method is called immediately when the TransformStream is created and is responsible for any initialization or setup required.
The transform() method is where the actual transformation work occurs. If this method returns a promise, transform() will not be called again until after that promise fulfills, which in turn will signal appropriate backpressure to the WritableStream side such that it will regulate the rate of inbound write requests.
The flush() method is called when the WritableStream side has been closed, giving the transformer an opportunity to complete any additional tasks it may need. For instance, compression and encryption transforms often have data remaining in internal queues that need to be flushed to the end of a ReadableStream.
Streaming across worker threads
One of the key new features of the web streams API that is not possible with the existing Node.js streams is a built-in ability to stream data across Node.js worker threads.
The ReadableStream, WritableStream, and TransformStream objects can all be easily transferred to a worker thread as illustrated in the example here:
import { ReadableStream } from 'node:stream/web'
import { Worker } from 'node:worker_threads'
const readable = new ReadableStream(getSomeSource())
const worker = new Worker('/path/to/worker.js', {
workerData: readable,
transferList: [readable],
})Then, in the worker.js code:
const { workerData: stream } = require('worker_threads')
const reader = stream.getReader()
reader.read().then(console.log)What is important to understand here is that the underlying source is still operating in the main thread, with the data it is provided being forwarded through the ReadableStream on to the worker thread. This happens "magically" under the covers through the use of a pair of MessagePort objects that connect the main thread ReadableStream to a connected ReadableStream created within the worker:
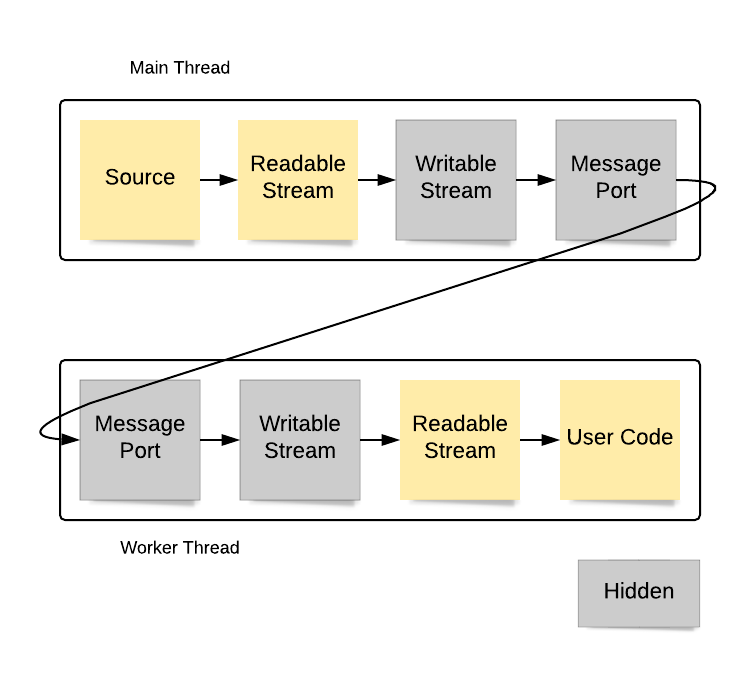
When a ReadableStream is transferred, an internal WritableStream is created in the same realm to which the data is piped. That WritableStream uses an underlying sink that forwards the data to a MessagePort that is entangled with a sibling on the worker thread side. When the entangled MessagePort receives the data, it writes that to a WritableStream that forwards it on to a ReadableStream for delivery to the user code.
The flow for WritableStreams is similar, except that the data flows in the opposite direction:
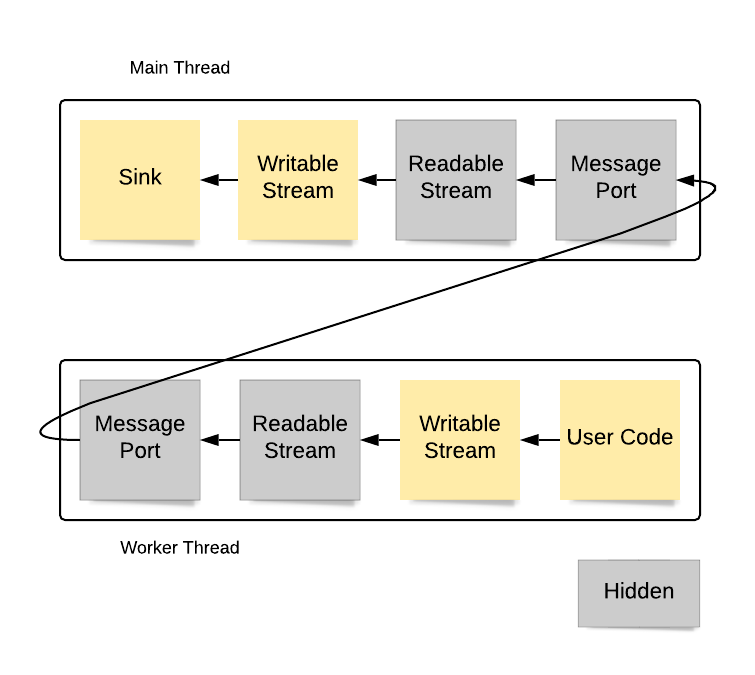
It is important to keep in mind that flowing the data across the worker thread boundary requires that the data be copied using the structured clone algorithm. This adds performance overhead and limits the kinds of data that can be passed back and forth.
The data flow for a transferred TransformStream is a combination of the two flows above:
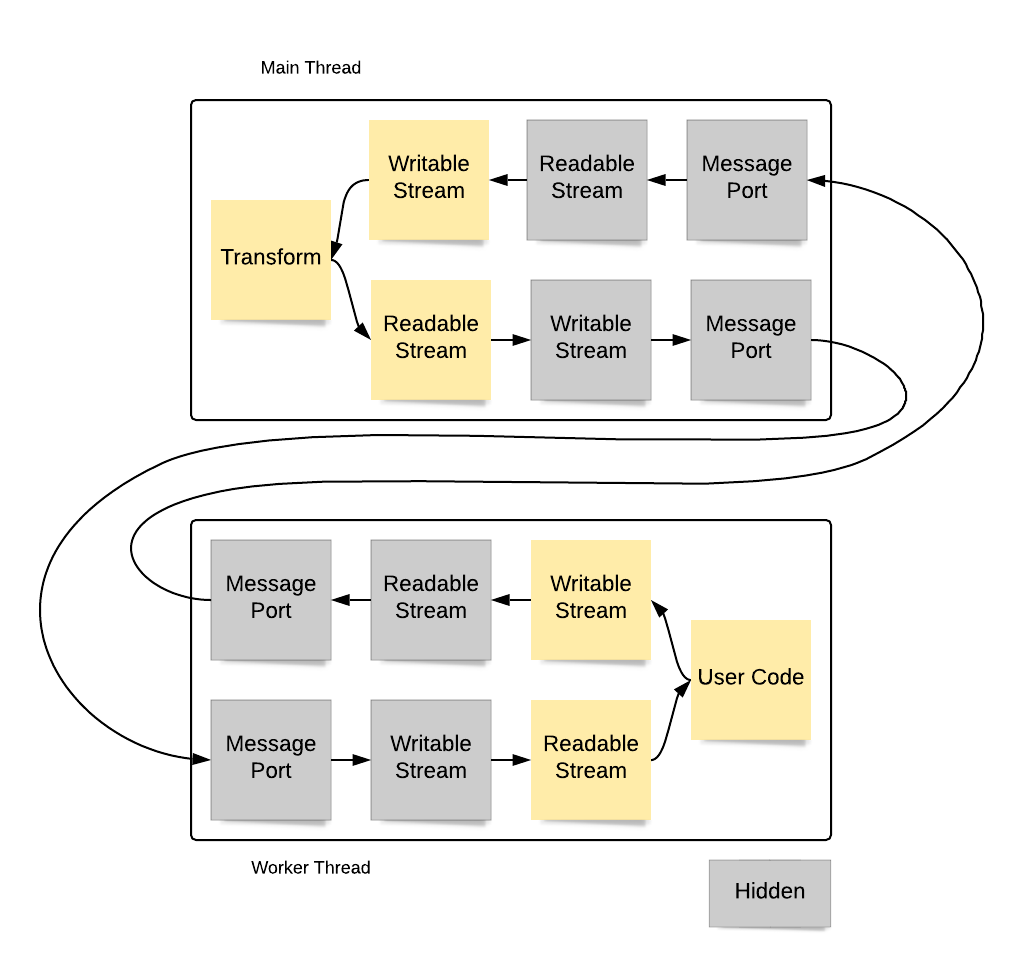
While there is certainly performance overhead in the data flow, a transferred transform can be a powerful way of offloading computationally expensive transformation algorithms to worker threads.
Because of limitations in the way the underlying v8 JavaScript engine has implemented the structured clone algorithm, as well as limitations in the way the Node.js module loader has been implemented, transferring web streams across the worker thread boundary is only possible with the web streams API built in to Node.js. polyfill or ecosystem implementations installable from npm cannot be transferred across the worker thread boundary.
Adapting to the Node.js Streams API
Anyone who has worked with Node.js for a while knows that there is an existing streams API that has existed in Node.js for quite some time. The web streams API is not meant to replace that existing API. Rather, web streams add a new, parallel API for working with streaming data such that code can be written that is portable to non-Node.js environments.
To make it possible to bridge the gap between the Node.js streams API and the web streams API, we have implemented experimental adapters that allow bi-directional compatibility between the approaches.
For instance, given a ReadableStream object, the stream.Readable.fromWeb() method will create an return a Node.js stream.Readable object that can be used to consume the ReadableStream's data:
import { Readable } from 'node:stream'
const readable = new ReadableStream(getSomeSource())
const nodeReadable = Readable.fromWeb(readable)
nodeReadable.on('data', console.log)The adaptation can also work the other way -- starting with a Node.js stream.Readable and acquiring a web streams ReadableStream:
import { Readable } from 'node:stream'
const readable = new Readable({
read(size) {
this.push(Buffer.from('hello'))
},
})
const readableStream = Readable.toWeb(readable)
await readableStream.read()Adapters for WritableStream to stream.Writable, and TransformStream to stream.Transform are also available.
Consuming web streams
As a convenience, a number of utility functions for consuming stream data (Node.js or web streams) are also being added. At the time this blog post is being written the pull request adding these has not yet landed but it is expected to make it into a release soon.
The utility methods are accessible using the 'stream/consumers' module:
import { arrayBuffer, blob, buffer, json, text } from 'node:stream/consumers'
const data1 = await arrayBuffer(getReadableStreamSomehow())
const data2 = await blob(getReadableStreamSomehow())
const data3 = await buffer(getReadableStreamSomehow())
const data4 = await json(getReadableStreamSomehow())
const data5 = await text(getReadableStreamSomehow())The argument passed into the utility consumers can be a Node.js stream.Readable, a ReadableStream, or any async iterable.
What's Next?
The web streams implementation in Node.js is still very much experimental. While it is feature complete and is passing the relevant web platform tests, there is still work to be done to optimize performance, integrate into the existing Node.js API surface, and ensure stability before the API can be declared stable for production use. Work on the web streams API implementation will continue.
What we need now are developers who can start using the API to provide feedback on the implementation. Are there bugs we haven't uncovered? Are there new kinds of adapters we need to implement?
Footnote
An older version of this blog post was originally written while I was at NearForm and may end up getting posted to the NearForm Insights blog also. I wasn't sure if they still intended on publishing it so decided to go ahead and publish here also.